|
 |
The Pulse: AI load breaks GitHub – why not other vendors?
GitHub’s leadership blames the 3.5x increase in service load as the cause of degradation – or it might be self-inflicted.
Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover Big Tech and startups through the lens of senior engineers and engineering leaders. Today, we cover one out of four topics from last week’s The Pulse issue. Full subscribers received the article below seven days ago. If you’ve been forwarded this email, you can subscribe here.
GitHub’s reliability has been beyond unacceptable recently: last month, third party measurements pinned it at one nine (right at 90%). This month, reliability has been down to zero nines – 86% – as per a third-party tracker, and last week, things got even worse: a frankly embarrassing data integrity incident, more outages, and a partial explanation from GitHub, eventually.
Data integrity incident
Last Thursday (23 April), this happened: PRs merged via the merge queue using the squash merge method produced incorrect merge commits, when the merge group contained more than one PR. Commits were reverted from subsequent merges: basically, commits were “lost” in the code that was merged!
Thanks to a bug GitHub introduced, the service broke its integrity promise that pull requests would be merged as expected when using squash merge, which is a technique typically used to merge multiple small commits into a single, meaningful commit. This is a big deal: as data integrity promises are some of the most important ones, for services like GitHub.
A total of 2,092 pull requests were impacted, and companies hit by the outage included Modal and Zipline. Effectively, GitHub pushed a bunch of work on affected customers who had to manually untangle and recover lost commits, which GitHub could offer zero assistance with.
Customers had to manually go through their git history and restore missing code. After following manual recovery steps (reverting the squash commit and re-applying commits one by one), all commits should have been recovered.
GitHub later emailed the list of affected commits to customers, but it’s odd that GitHub executives seemed to downplay the nature of this outage. After all, an outage that messes with data integrity is a much bigger deal than something like a fall in availability where no data is corrupted.
Can Duruk, software engineer at Modal, was unhappy about GitHub’s muted response to the outage:
“The COO going out of their way to find a huge denominator to make the impact appear small feels very dishonest; versus a sincere apology about how this invalidates their entire promise to their customers. We had to dig into their status page about this to even realize they just casually f***ed up our repo.”
Outages don’t stop
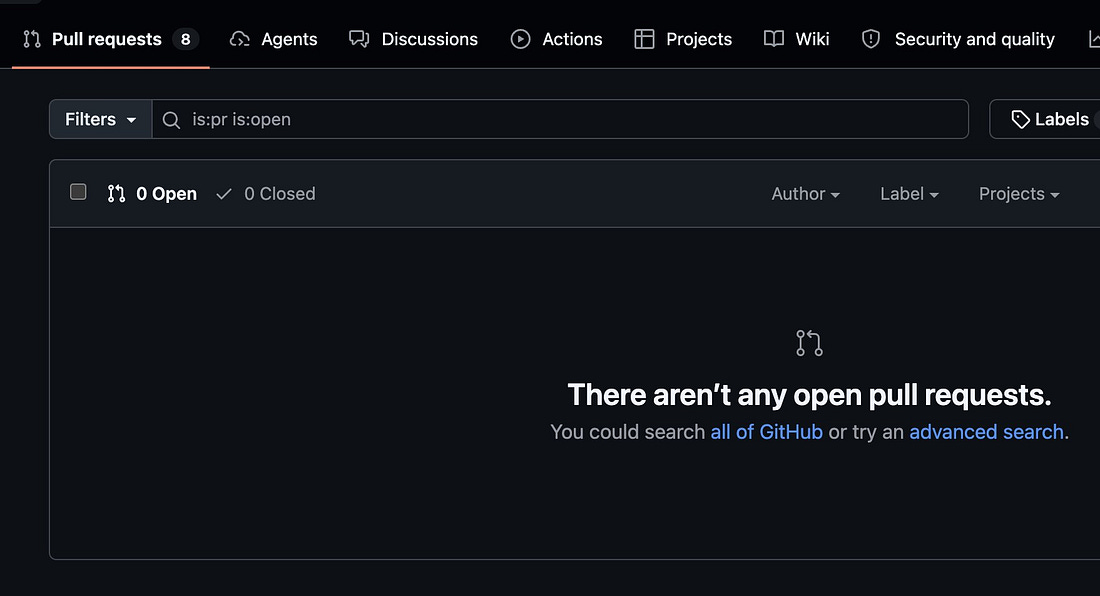
On Monday (27 April), pull requests and issues disappeared from GitHub’s web UI:
 |
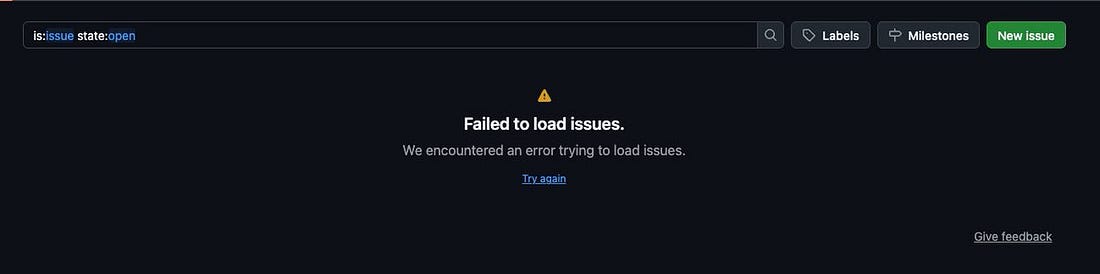 |
This had to do with an Elasticsearch outage on GitHub’s backend: the cluster became overloaded and went down. So, while pull requests, issues, and projects didn’t vanish altogether, they also didn’t show up during the 6-hour-long outage.
There were other outages this week:
Some pull requests not showing up (Tuesday, 28 April)
Problems with some GitHub Actions (the same day)
Incomplete pull requests in repositories (Wednesday, 29 April)
Also on Tuesday (28 April), security firm Wiz disclosed a critical security issue, where a bad actor could get access to all repositories on GitHub and GitHub Enterprise server by using only a git push command. GitHub fixed the issue on GitHub.com within six hours, but GitHub Enterprise servers that were not updated remain vulnerable.
Famous open source contributor quits GitHub in frustration
On Tuesday, Mitchell Hashimoto, founder of HashiCorp, creator of Ghostty, announced GitHub was unfit for professional work and that he was moving off to Ghostty, the open source terminal that’s his main focus. Mitchell’s reasoning was dead simple: being on GitHub makes him unproductive (emphasis mine:)
“The past month I’ve kept a journal where I put an “X” next to every date where a GitHub outage has negatively impacted my ability to work. Almost every day has an X. On the day I am writing this post, I’ve been unable to do any PR review for ~2 hours because there is a GitHub Actions outage. This is no longer a place for serious work if it just blocks you out for hours per day, every day.
It’s not a fun place for me to be anymore. I want to be there, but it doesn’t want me to be there. I want to get work done and it doesn’t want me to get work done. I want to ship software and it doesn’t want me to ship software.
I want it to be better, but I also want to code. And I can’t code with GitHub anymore. I’m sorry. After 18 years, I’ve got to go. I’d love to come back one day, but this will have to be predicated on real results and improvements, not words and promises.”
Mitchell’s experience suggests that GitHub’s official status page is inaccurate from the point of view of a heavy user like himself. The third-party “missing GitHub status page” is likely to be a better estimation: wh